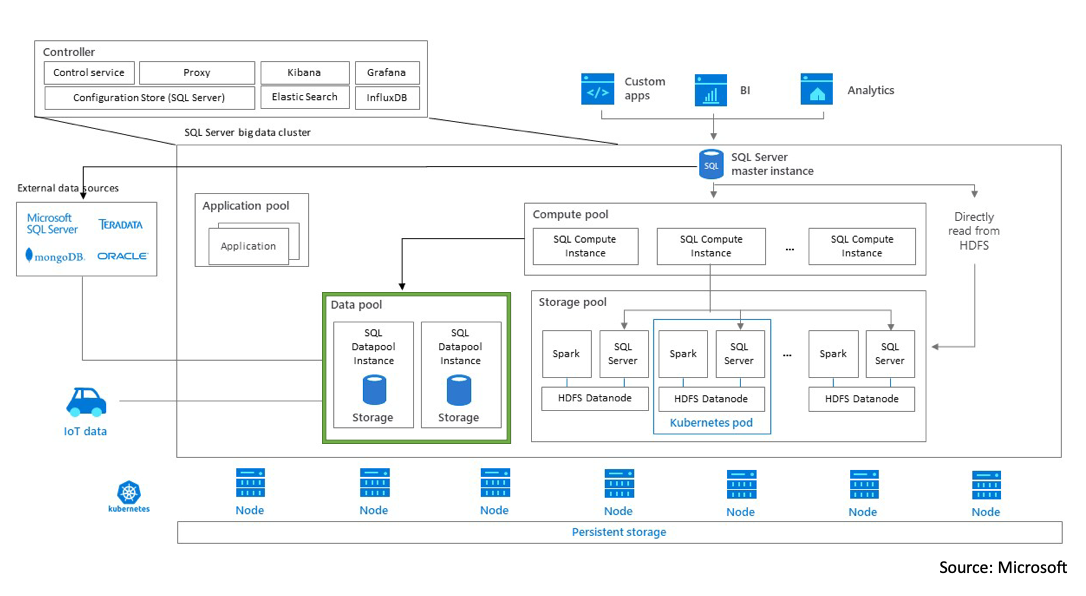
One of the key components of a Big Data Cluster is the data pool. Within that single data pool, there are two SQL Server instances. The primary job of the data pool is to provide data persistence and caching for the Big Data Cluster. (At the time of this blog post, there can only be a single data pool in a Big Data Cluster and the maximum supported number instances in a data pool is eight.) The instances inside the data pool do not communicate with each other and are accessed via the SQL Server Master instance. The data pool instances are also where data marts are created.
You can watch the video below (or continue reading):
Scale-out data marts
Data pools enable the creation of scale-out data marts. Whether your data is being ingested from Spark jobs or SQL, it is stored into the data pool. Data is distributed across one, or two, SQL Server instances running queries against it is more efficient.
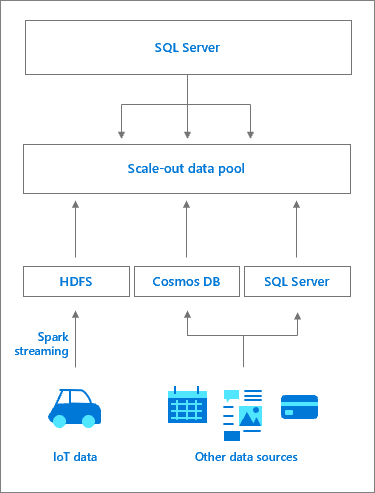
Whether the data is being ingested from IoT device, Kafka, another relational data source (like Oracle or Teradata), it all is stored into the data pool instances and are available as “data marts” for the consumer to work with. There is no need to go back out to the original data source each time you want to query the data. It is all available inside the data pool instances.
In a future CU (Cumulative Update) you will have the option to scale the number of data pools. When that time does come you will have to recreate your data pool tables. For example, if you decide to go from 2 instances in the data pool to 4 instances, you will have to recreate the table across all 4 data pool instances since there will be a skew of data.
More Data Pool Scenarios
In addition to providing data persistence and caching, some other scenarios for using the data pool instance are:
- Complex Query Joins – If you run a complex query that joins multiple data sources (like SQL Server with Oracle and MongoDB, etc.), or if the data source is on a much slower infrastructure (network latency, etc.) then running it against the data pool would be better.
- Machine Learning – If you are training data models, it would be ideal to run that against the data pool and not the SQL Server Master instance. Then, the data scientist can run all their prep/training against the data pool instances and not use up the SQL Server Master instance resources.
- Reporting – If you have a report running that calculate HDFS data, or any other data source, you can point that to the data pool instances.
Persist Data to the Data Pool
The method in which data can be persisted to the data Pool instances is via the EXTERNAL command when creating a table. For example, let’s say there is data you want to insert into a table in the data Pool. First, you’ll need to create the external data source (SqlDataPool) as shown in be code snippet below:
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlDataPool') CREATE EXTERNAL DATA SOURCE SqlDataPool WITH (LOCATION = 'sqldatapool://controller-svc/default');
Once the external data source is created, you can go ahead and create an external table and point to the external data source created above:
IF NOT EXISTS(SELECT * FROM sys.external_tables WHERE name = 'web_clickstream_clicks_data_pool')
CREATE EXTERNAL TABLE [web_clickstream_clicks_data_pool]
("wcs_user_sk" BIGINT , "i_category_id" BIGINT , "clicks" BIGINT)
WITH
(
DATA_SOURCE = SqlDataPool,
DISTRIBUTION = ROUND_ROBIN
);
Now you can use the above external table (web_clickstream_clicks_data_pool) to insert data into.
Notice that the WITH clause has the “DATA_SOURCE” parameter that points to the SqlDataPool external data source. It also include a DISTRIBUTION parameter that equals to ROUND_ROBIN. Let’s talk a little about distribution policies below.
Distribution Policy
Currently, there are two distribution policies when you create an EXTERNAL table: Round Robin or Replicated. One thing to note is data distribution is managed from the SQL Serve Master instance.
- Round Robin – The data is split between the sharded tables in the data pool instances. So, for example, if you have a 100 rows, 50 rows will be inserted into data pool instance 1 and the remaining 50 rows will be inserted into data pool instance 2.
- Replicated – This distribution type is usually for reference tables or dimension tables. Usually small tables that you want on all data pool instances. Copy of data in every instance.
Kubernetes Data Pool Internals
Let’s take a look at what container services are running on the data pool pod. First thing to do is run the below command to get a list of all the pods in the cluster:
kubectl get pods -n mssql-cluster
And you will get the pods that are part of the “mssql-cluster” namespace. Here is my output:
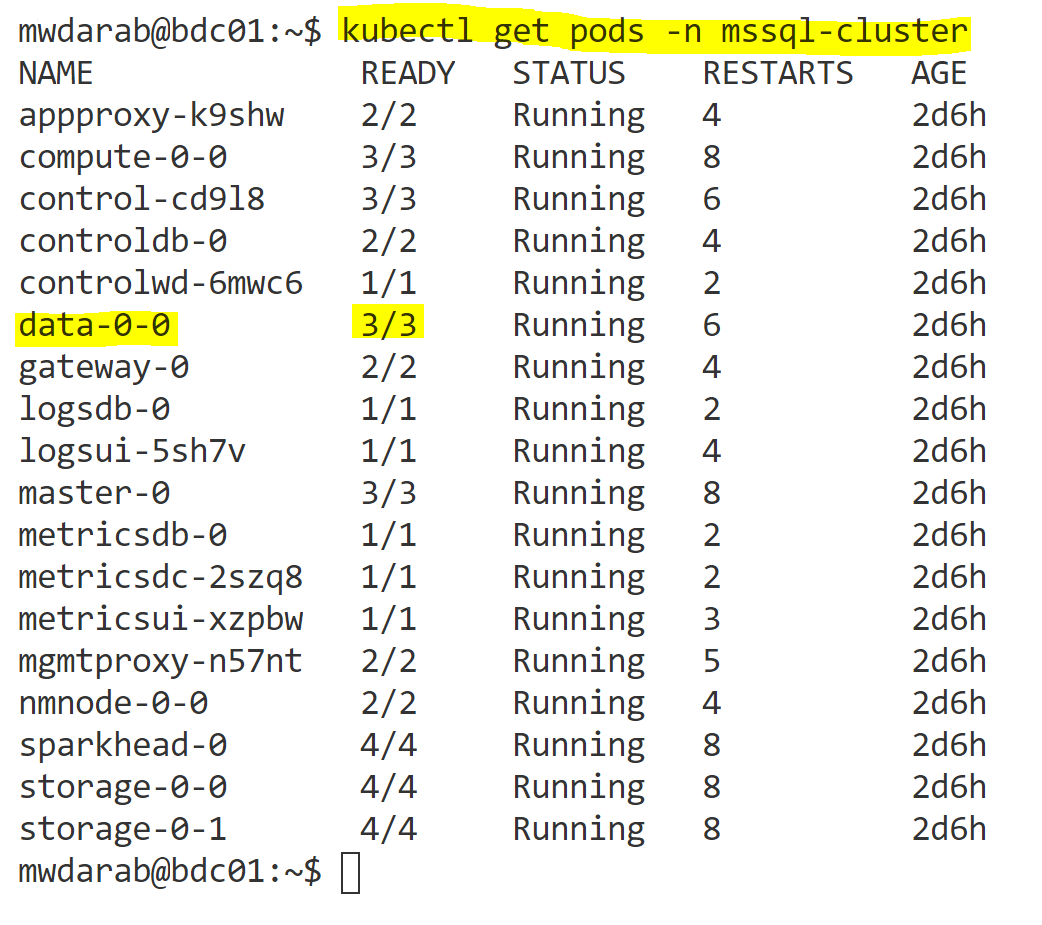
So the command above will print out all the pods in the mssql-cluster namespace. The specific pod we are concerned about is highlighted: data-0-0
That is the pod running in the data pool. The “3/3” means there are 3 out of 3 containers running in that single data-0-0 pod. Let’s take a deeper look at what those 3 container services are by running the below command:
kubectl describe pod data-0-0
The output of the above command is quite verbose so I will include two snapshots below:
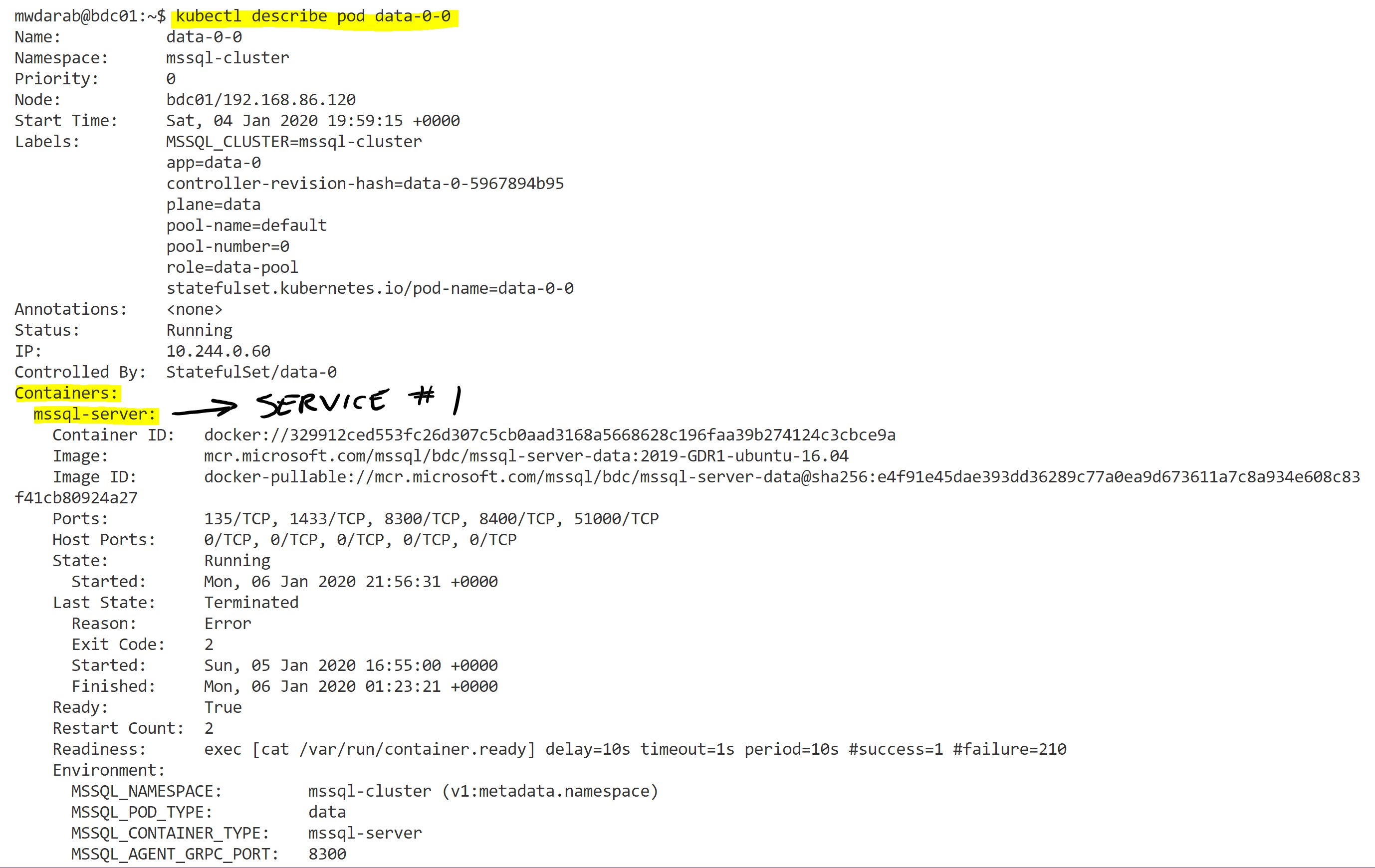
If you look at the output you will see I highlighted “Containers:” and right below that is “mssql-server”. That is the first container service running in the data pool pod (data-0-0). The second portion of the printout is below:
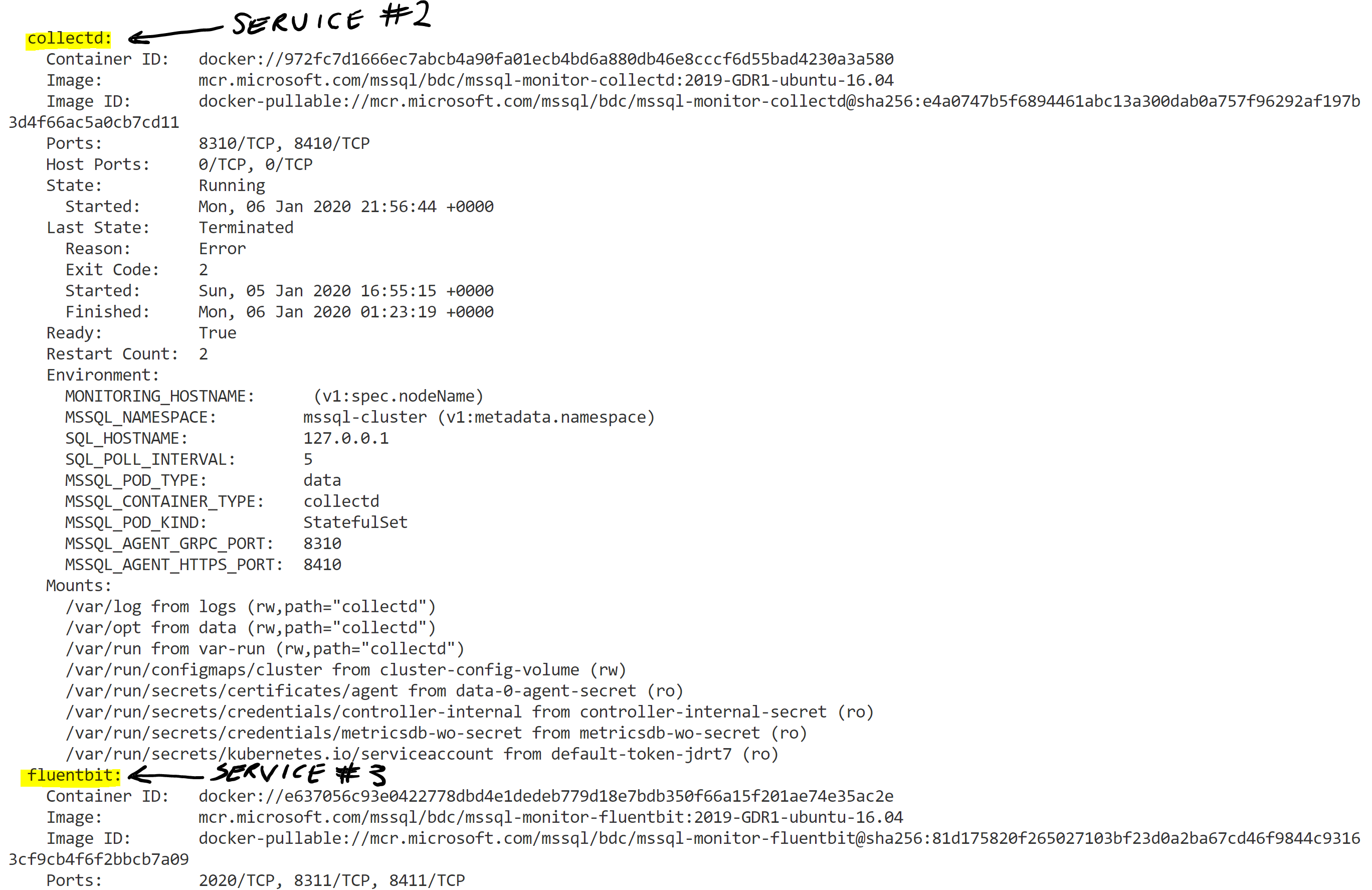
I highlighted service #2 (collectd) and #3 (fluentbit).
What is Fluent Bit and collectd?
Fluent Bit – In short, Fluent Bit is an open source log forwarder tool. It collections logs and distributes them. It is a very lightweight service and comes with full Kubernetes support. You can read more about Fluent Bit here.
collectd – collectd gathers metrics from various sources like the operating system, applications, log files and external devices. These statistics can be used to monitor systems, find performance bottlenecks and assist with capacity planning. You can read more about collectd here.
That’s a wrap!
Great content from a users perspective, told me what a Data pool is compared to the BDC docs that tries to tell me what it is!
Thank you!