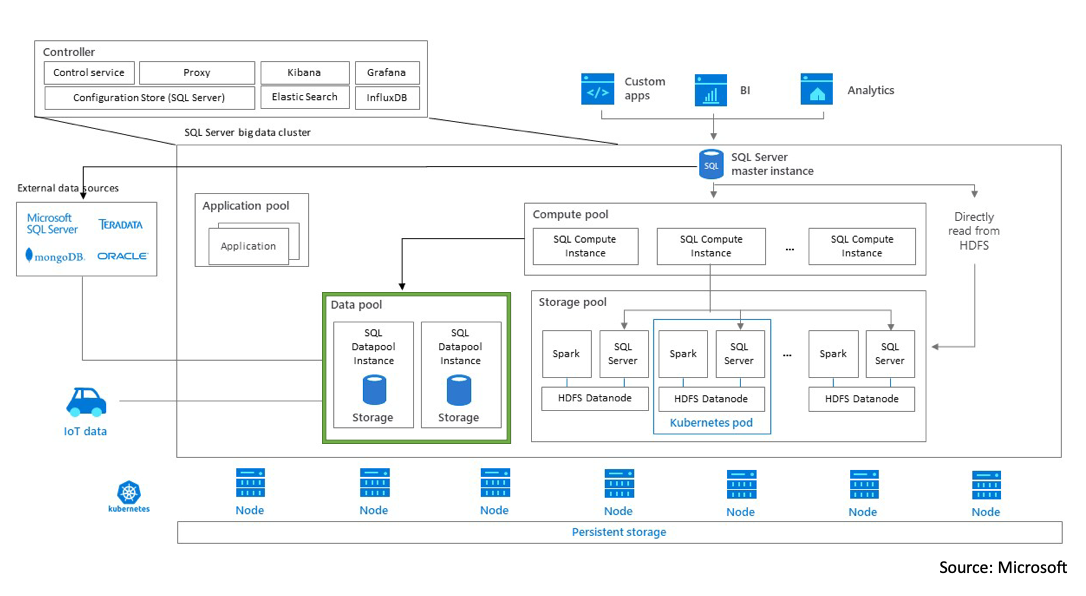
I wanted to publish a quick note about something a little near and dear to me. As of today, Feb 25th, 2022, Microsoft made the official announcement that they are retiring SQL Server Big Data Clusters. You can read the full statement here.
“Support for SQL Server 2019 Big Data Clusters will end on January 14, 2025.”
Quite frankly, to me, this is sad news. I was awarded my Microsoft MVP because of the work I did with Big Data Clusters. From speaking to blogging and creating videos on the topic.
On the bright side, during my time speaking and talking about BDCs, I met some amazing people and made some great friendships.
Remember, technologies come and go but networking, meeting new people and making friends are forever.
Bye Bye BDC.
 If only there was a feature that would allow me to stop the VMs in AKS whenever I wasn’t using them. Well, I’m excited to share that Microsoft AKS (Azure Kubernetes Service) came out with a neat feature (currently in preview at the time of the publishing of this post) that allows you to stop and start your AKS cluster by running a simple command. Of course I had to try it out on BDCs and to my surprise it worked. Well, sort of. Let me explain…
If only there was a feature that would allow me to stop the VMs in AKS whenever I wasn’t using them. Well, I’m excited to share that Microsoft AKS (Azure Kubernetes Service) came out with a neat feature (currently in preview at the time of the publishing of this post) that allows you to stop and start your AKS cluster by running a simple command. Of course I had to try it out on BDCs and to my surprise it worked. Well, sort of. Let me explain…