So you want to play around with a Big Data Cluster but on a strict budget? No problem! Keep reading or watch the video below.
If you are interested in deploying a Big Data Cluster on a multi-node kubeadm cluster, check out my post here.
Minimum Requirements
This blog post will walk you through deploying a SQL Server Big Data Cluster on a single node Kubernetes cluster. You can install a Big Data Cluster on a physical machine or a virtual machine. Whatever option you choose must have the below minimum requirements:
- 8 cpu
- 64 GB RAM
- 100 GB disk space
My Hardware
I had to go “old school” and purchase a used server off eBay. I say old school because last time I purchased something off eBay was mid 2000s. The server I purchased can be found here. (image below) This server is at least 75 lbs and when I first booted it up, my wife thought I turned on the vacuum cleaner. It does quiet down once it’s running, but the boot-up process is LOUD!

The specs on my server are two 12 core processors (total of 24 physical cores), 320 GB RAM and 1.2 TB of storage. That is *more* than enough to deploy Big Data Clusters. Now for the software…
Software
When it came to software I debated between Windows Hyper-V and VMware vSphere. I ended up going with VMware vSphere (6.7). I also download the Ubuntu Server 16.04 iso file. Links to those two are below:
- VMware vSphere 6.7 download link
- Ubuntu Server 16.04 iso (direct download link)
However you setup your virtual machine is up to you. As long as it has the minimum requirements you’ll be good to go. If you like to watch me set mine up via vSphere, watch the video above.
Deploying the Big Data Cluster
Microsoft has provided a script that deploys a single node Kubernetes cluster, then deploys a Big Data Cluster on top of that. I highly recommend reading through the script and getting a better idea of what is happening. I will create another video (and blog) on that. But in the meantime, let’s walk through the deployment below:
First – Log into your Ubuntu Server 16.04 virtual machine and execute the following commands to grab the latest updates and reboot the machine:
sudo apt update && sudo apt upgrade -y sudo systemctl reboot
Second – Log back into the VM and run the below command to download the script onto your machine:
curl --output setup-bdc.sh https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/deployment/kubeadm/ubuntu-single-node-vm/setup-bdc.sh
Third – Make the script you just downloaded executable by running the following command:
chmod +x setup-bdc.sh
Fourth – Run the script with sudo:
sudo ./setup-bdc.sh
You will be prompted for a password. This password will be used for the Controller, SQL Server master instance and the gateway. The username defaults to admin.
This script will take some time (between 15-30 minutes). Once it is done, you will see a list of endpoints like below:
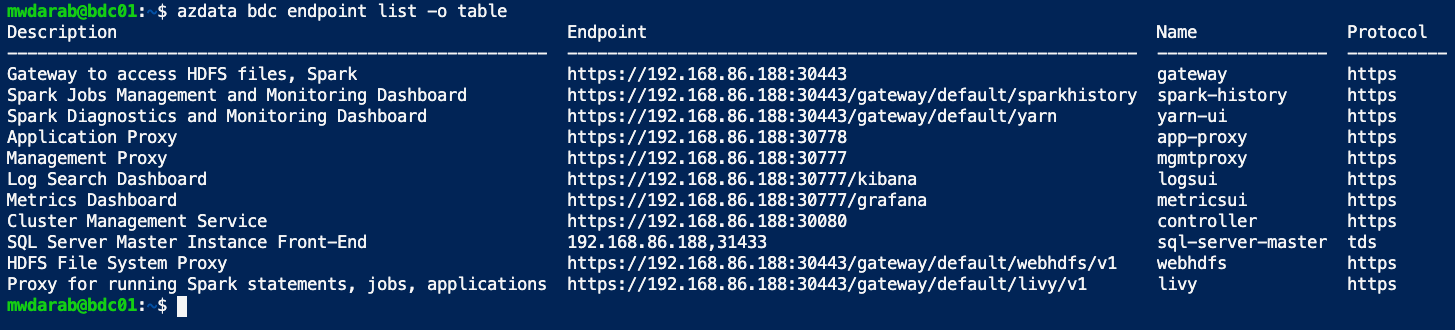
If you would like to view your endpoints, you can do so by running the below commands:
First, log into azdata by running:
azdata login
Once prompted, enter the namespace, username and password. Then run the command below:
azdata bdc endpoint list -o table
This will list out your endpoints in table format.
Now you can copy the “SQL Server Master Instance Front-End” endpoint (ip address and port) and paste it into Azure Data Studio or SSMS and start playing around with your single node Big Data Cluster.
If you are interested in deploying a Big Data Cluster on a multi-node kubeadm cluster, check out my post here.
Enjoy!
Hi Mohamed. I’m getting flowing error,
$ sudo ./setup-bdc.sh -x
Create Password for Big Data Cluster:
Confirm your Password:
./setup-bdc.sh: line 346: syntax error: unexpected end of f
Hi Mohammed, I’m a DBA, trying to learn this, and found your demo very informative. I followed your instructions for a single Node, but got the following authentication 401 error after doing the Azdata step – “HTTP response headers: HTTPHeaderDict({‘WWW-Authenticate’: ‘Basic realm= “Login credentials required”, Bearer error=”invalid_token”, error_description=”T he token is expired”‘
Hello Manuel,
I’m glad you found this blog post informative. To resolve your error, try first typing: azdata login
and logging with your cluster name (mssql-cluster) and your username/password. Once it logs in successfully, you should be able to type: azdata bdc endpoint list -o table and get a list of your endpoints.
If that doesn’t work, feel free to email me and I’ll work with you to resolve it. Thanks for the comment! I updated the blog post accordingly.
I’m getting the same issue as Tom. Using VMWare Fusion on a powerful macbook pro I setup an Ubuntu server 16.04 with 8 cores and 64 GB ram. It gets through most of the install but at the end it hangs with:
Starting cluster deployment.
Cluster controller endpoint is available at 192.168.219.135:30080.
Cluster control plane is ready.
Data pool is ready.
Storage pool is ready.
Compute pool is ready.
Master pool is ready.
Cluster is not ready after 15 minutes. Check controller logs for more details.
Cluster is not ready after 30 minutes. Check controller logs for more details.
Do you know how to access the controller logs off hand? It doesn’t seem to be trivial. Thanks.
Mark, what do you get when you run a “kubectl get pods”? Feel free to contact me (contact page) and we can further troubleshoot.
Update: I figured it out. I followed the procedure listed at https://docs.microsoft.com/en-us/sql/big-data-cluster/cluster-troubleshooting-commands?view=sql-server-ver15 to view the pods, see which ones had problems, then export the logs.
Turns out it was a DNS problem. The default VMWare Fusion networking method is “share with my mac” — that doesn’t work for BDC. I had to choose local wifi network instead, then it installed without issue.
Great news! I’m glad you figured it out!
I exactly followed your deployment several times but still getting “Cluster is not ready after xx minutes.”. Is the whole procedure still working for you as of today?
Hello Tom, Yes it does still work for me. What version of azdata are you running? Feel free to contact me (use the contact page) so we can further troubleshoot.