There is something about high performance tuning that I find very fascinating. Performance tuning your database server is one of those things that you cannot just pinpoint to a single cause. You must have an overall understanding of how SQL Server internals work to really understand all the areas that you can “tune”, how they all interplay with each other, etc. Without having a grasp on this crucial subject, you will find yourself scratching your head more times than not when learning performance tuning. Continue reading “Book Review – “High Performance SQL Server” by Benjamin Nevarez”
Interview – Kendra Little
I decided to start a series of blogs where I interview key people in the SQL Server community. Instead of me asking technical questions, I plan on asking about their outlook on the future, books they read (non-fiction and/or technical), and their overall thoughts on where technology (mainly SQL Server) is headed. You can find more interviews here.
Next up: Kendra Little (b | t):

Mohammad: Where do you see SQL Server technology evolving to 5 years from now? More cloud focused?
Kendra: Over five years time, I think we will see a “normalizing” of many of the more recent advancements we’ve had in the technology. So yes, I think there will be more people using the cloud as those features continue to mature. Continue reading “Interview – Kendra Little”
Interview – Adam Machanic
I decided to start a series of blogs where I interview key people in the SQL Server community. Instead of me asking technical questions, I plan on asking about their outlook on the future, books they read (non-fiction and/or technical), and their overall thoughts on where technology (mainly SQL Server) is headed. You can find more interviews here.
Next up: Adam Machanic (b | t):

Mohammad: Where do you see SQL Server technology evolving to 5 years from now? More cloud focused?
Adam: Over the next five years there will definitely be a continued push toward the cloud. And this only makes sense; competition will continue to drive down pricing (albeit slowly), and for most companies, at some point it will simply become fiscally unwise to continue with the cycle of managing and replacing a large amount of in-house hardware. Continue reading “Interview – Adam Machanic”
Interview – Chrissy LeMaire
I decided to start a series of blogs where I interview key people in the SQL Server community. Instead of me asking technical questions, I plan on asking about their outlook on the future, books they read (non-fiction and/or technical), and their overall thoughts on where technology (mainly SQL Server) is headed. You can find more interviews here.
Next up: Chrissy LeMaire (b | t):

Mohammad: Where do you see SQL Server technology evolving to 5 years from now? More cloud focused?
Chrissy: I’m the opposite of a visionary and really have no idea. That being said, five years doesn’t seem very long; I think it’ll take closer to 10 years for to fully realize the cloud thing. Microsoft may be cloud-focused, but the industries I work in are still very on-premises when it comes to Microsoft software. Continue reading “Interview – Chrissy LeMaire”
Interview – Tim Radney
I decided to start a series of blogs where I interview key people in the SQL Server community. Instead of me asking technical questions, I plan on asking about their outlook on the future, books they read (non-fiction and/or technical), and their overall thoughts on where technology (mainly SQL Server) is headed. You can find more interviews here.

Mohammad: Where do you see SQL Server technology evolving to 5 years from now? More cloud focused?
Tim: I see the cloud focus still ongoing. Within 5 years, I see more small to mid-size companies embracing Cloud rather than building out their own large datacenters. Analytics will continue to be a strong focus as companies need to trend their data. Continue reading “Interview – Tim Radney”
Interview – Brent Ozar
I decided to start a series of blogs where I interview key people in the SQL Server community. Instead of me asking technical questions, I plan on asking about their outlook on the future, books they read (non-fiction and/or technical), and their overall thoughts on where technology (mainly SQL Server) is headed.

Mohammad: Where do you see SQL Server technology evolving to 5 years from now? More cloud focused?
Brent: Today, in early 2017, the majority of shops are still on SQL 2008/2008R2.
That means in 2022, most shops will be running 2012/2014 – which means Always On Availability Groups will be more widespread, for example. But other than that, I don’t think the world is going to be very different for SQL Server DBAs. A lot of their databases will probably run in the cloud, but for the most part, VMs in the cloud aren’t that different from VMs on-premises.
Google Wifi Review
Wifi routers have always been a pain in the butt for me. I live in a 3-level townhouse and it’s always been a challenge to evenly distribute the internet across all three floors. Over the past 10-15 years, I’ve tried multiple routers. From name brands like the old Linksys WRT54G router and Apple Airport Extreme, to the lesser known Almond+ by Securifi. The Almond+ was actually great when compared to the rest. The setup and wifi reception was great. The only downside was the router was on the third floor, so the internet speed in the basement was horrible. I started to do more research on how to evenly distribute the wifi and came across products like eero, and Google Wifi. These products offer a “3 pack” of routers that work together to give you evenly distributed internet reception. Continue reading “Google Wifi Review”
Stuff and Replace Function in SQL Server : Detailed Description
(This is a guest blog post by Daniel Jones (li | t | fb). Daniel is a SQL Server DBA and contributor at SQL Tech Tips. Having 2 + years of experience in SQL recovery and system infrastructure.)
In SQL Server, STUFF and REPLACE functions are used to replace the characters in a string. Both functions play an important role in Transact-SQL with performing the distinct functionality. In the following section, we are going to discuss about Stuff and Replace function in detail. Continue reading “Stuff and Replace Function in SQL Server : Detailed Description”
Error 3241 in SQL Server
(This is a guest blog post by Daniel Jones (li | t | fb). Daniel is a SQL Server DBA and contributor at SQL Tech Tips. Having 2 + years of experience in SQL recovery and system infrastructure.)
Microsoft SQL Server Backup Error Code 3241 Restore Headeronly
Sometimes, the users of MS SQL server faced an error when they try to restore SQL database from the backup file in the SQL server. This error is known as SQL server error 3241 and it generates the below-mentioned error message.
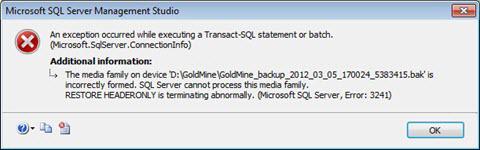
Due to this error message, the users cannot restore the data from the backup file into SQL Server database. Therefore, in this post, we are going to discuss the reason for the occurrence of error 3241 and the relevant solutions to resolve the error. Continue reading “Error 3241 in SQL Server”
What Should My Salary Be?
What Should My Salary Be?
There are two questions that you just don’t ask people. It can create animosity and can even cause relationships to break. One of those questions is, “how much do you make?” Continue reading “What Should My Salary Be?”
FREE Microsoft eBooks!
Sometimes the best stuff is FREE!
I recently came across this Microsoft site when I was searching for whitepapers. It’s part of the Microsoft Virtual Academy. They not only have free ebooks, but they also have free virtual courses. Continue reading “FREE Microsoft eBooks!”
How To Study Smarter Not Harder
How To Study Smarter Not Harder
One of my “New Year resolutions” is to increase my knowledge. As an IT professional, it is crucial to stay abreast with the constant changes in technology. The new replaces the old and by the time you get around to learning the new, that becomes old. As someone who works closely with SQL Server, I find it extraordinarily cumbersome to stay abreast of the new trends and technologies. Just SQL Serve 2016 alone has so many cool new features. Imagine the constant updates with Microsoft Azure. All that can be demotivating. Continue reading “How To Study Smarter Not Harder”
How To Decrypt Stored Procedure In SQL Server
I recently had to view the code behind a couple stored procedures in SQL Server. Usually that’s a very simple thing to do. Just right click the stored procedure, click Modify OR script-as “Create New” and it spits the entire stored procedure in a query window. Unfortunately for me, the stored procedures were encrypted so the usual method mentioned above did not work. Continue reading “How To Decrypt Stored Procedure In SQL Server”
Your 5 Favorite Blog Posts of 2016
Here are the top 5 blog posts of 2016:
1. How to Find Last Login Date of a SQL Server Login? – This was by far the most clicked on blog. It looks like a lot of people need to secure their SQL Server environments :)
2. How to Request a DoD Server Certificate – Working in the DC area, I have a lot of experience working with DISA STIGS, securing and hardening SQL Server. Continue reading “Your 5 Favorite Blog Posts of 2016”
Blog Stats – 2016
Finally! A full year of traffic. I aimed to blog at least once every few days but fell short. I plan on blogging a lot more in 2017, especially with the release of SQL Server 2016 and all the cool new features it has.

As you can see, 2016 was a 780% increase of page views compared to 2015. Continue reading “Blog Stats – 2016”