If you’d like to stay updated, without doing the heavy work, feel free to register for my newsletter. I will email out blog posts of my journey down the wonderful road of BDCs.
When I think of SQL Server 2019, I think of BIG DATA CLUSTERS. I remember first hearing the term and immediately thinking, “eh, what does that have to do with a Windows SQL DBA?” But the more I thought about it, the more I fell in love with it. And here’s why:
First: the entire market is shifting more and more towards the cloud. Whether you personally believe it or not, or like it or not, it is happening. In 3-5 years from now, majority of jobs on the market will require some level of cloud knowledge (Azure, AWS, etc.)
Second: over the past few version of SQL Server (2016+) it’s apparent that Microsoft is pushing SQL Server down the path of becoming “OS agnostic.” By that I mean it will no longer matter what the underlying OS is. Windows? Linux? Who cares? SQL Server will run on it all!
Third: Microsoft has a game plan and I want to play a part!
Now if your background is a Windows DBA, like myself, you probably don’t care about learning how to install SQL on Linux, let alone trying to install SQL on Linux via Docker Containers. All of that may seem unnecessary to you. Or perhaps, you are interested in learning the above-mentioned topics but don’t know where to start or need that extra guidance.
That’s where the new SQL Server 2019 Big Data Clusters comes to “save the day.”
I will explain how BDCs “save the day” at the end of this blog post, but for now let start with defining what Big Data Clusters are…
The Microsoft Definition
Big Data Clusters is new in SQL Server 2019 and the more I dig into it the deeper the rabbit hole gets. First, here’s Microsoft’s description of what a Big Data Cluster is:
SQL Server big data clusters allow you to deploy scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes. These components are running side by side to enable you to read, write, and process big data from Transact-SQL or Spark, allowing you to easily combine and analyze your high-value relational data with high-volume big data.
SQL Server big data clusters provide flexibility in how you interact with your big data. You can query external data sources, store big data in HDFS managed by SQL Server, or query data from multiple external data sources through the cluster. You can then use the data for AI, machine learning, and other analysis tasks.
Big Data Cluster Architecture
A few components make the Big Data Cluster work. Below are some of the major components that BDCs utilizes.
Containers – Microsoft introduced SQL on Linux back in 2017, and in 2019 you could install SQL Server on Docker containers. Everything about the Big Data Cluster is “containerized.” So every instance of SQL (irrespective of what pool it’s in, see below) is in its own container. If you’re wondering, “why containers?” How else could you use Kubernetes to “orchestrate” those containers?
Kubernetes – Kubernetes acts as the container orchestration service. Kubernetes plays a pivotal role in how the BDC works by acting as the “container orchestrator” or the so-called brains behind the Big Data Cluster. It is in charge of scaling out the different “pools” of pods. Here are some Kubernetes concepts:
- Cluster – A set of nodes. Usually there is a single master node and many worker nodes.
- Node – Think of a node as a physical or VM
- Pods – A pod is the smallest unit in Kubernetes. There can be multiple pods in a node
Each group of pods/nodes/containers are further divided into “pools”:
- Compute pool – These are a bunch of SQL Server pods (or instances) that can distribute the query load among them.
- Storage pool – This is a scalable storage tier
- Data pool – These group of SQL Server pods can be used to cache data for faster retrieval
- Master pool – This can be either a single instance of SQL Server or multiple instances in an Availability Group for HA and read scale out. This is where the read-write is stored in the BDC
Big Data Cluster Benefits
Here is a list of Big Data Cluster benefits and scenarios:
- If you want a SQL + big data solution from Microsoft outside of Azure then the only option is SQL 2019 BDC. That’s probably obvious, but maybe not relevant to this particular customer you are talking to because they want to be in Azure.
- If you want a consistent solution to use in Azure, outside of Azure (on prem, AWS, etc) then you can use BDC in both places.
- If you want more control, less lock in, more flexibility, etc. by using IaaS then you can use BDC on kubeadm on Azure IaaS or AKS. This is essentially the same as customers choosing to use SQL in IaaS instead of PaaS.
- If you want an integrated solution of SQL + Spark + HDFS then BDC is a good option. Otherwise you are trying to connect together different services in Azure (DW, ADLS, Databricks, HDI) to do the same thing.
- There is no ML Services in SQL DW today. ML Services in SQL DB is in preview. ML Services is built into BDC master.
In addition, with BDCs you can use one tool – Azure Data Studio to do the following:
- Cluster administration
- Notebooks
- T-SQL
- Spark
- Local Python
- SQL Server stuff
- Browse schema, create and run queries, create dashboards, etc
- HDFS file system tasks
- Upload/download files
- Preview files
- Right click – create external table
- Right click – analyze in notebook
- ACL folders/directories
- Manage “data apps”
- Deploy R, Python apps
- Deploy SSIS jobs
There is also one CLI – azdata – to do all of the above.
In Azure services, you would have to use many different GUIs and CLIs to do this:
- Azure Databricks notebooks
- SSMS and/or ADS
- HDI
- Azure Storage Explorer
- etc.
Imagine, you have legacy apps, BI integration and datamarts, some in AWS, some in Azure, Oracle and even big data in HDFS. With BDCs you have the ability to tie all this data together WITHOUT moving the data. You can create a “data hub” to run analysis against all in one single location. You just connect to them via Polybase.
What Is Really Unique About BDCs
The *absolute* unique feature that BDCs offer that *no* other company or product offers is: Data Virtualization
The new and enhanced SQL Server 2019 Polybase feature comes with connectors to many different data sources: Oracle, Teradata, Apache Spark, MongoDB, Azure Cosmos DB, and even ODBC connectivity to IBM’s DB2, SAP HANA and excel (see image below)
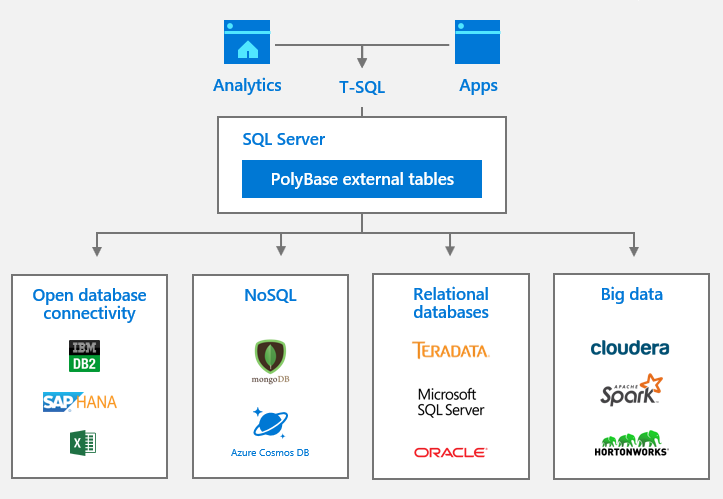
Now there is no need for ETL processing. You can “virtualize” the data in a SQL Server instance so that it can be queried there like any other table in SQL Server. The data in Oracle (for example) can remain in Oracle. You just query it from SQL Server. That is huge!
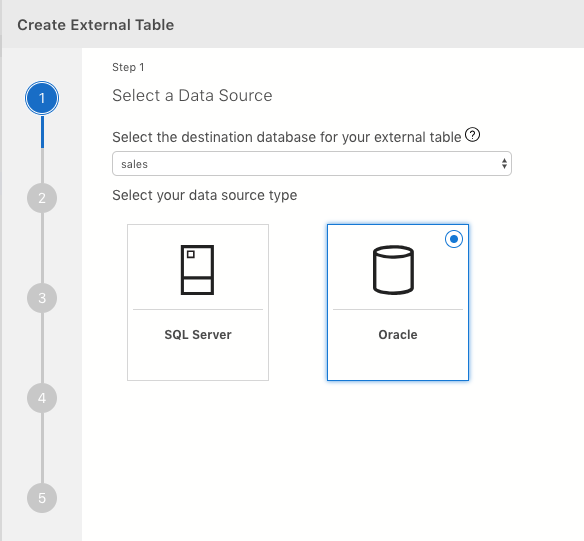
You can use the “Virtualize Data wizard” to guide you through creating an “external table.” Right now the only option available is to create an EXTERNAL table to Oracle (see image below). Microsoft is working on creating more options in the near future.
BDCs Are Here To Save The Day
Confused yet? No worries. So was/am I. Ha! Being a Windows SQL DBA and learning about Big Data Clusters will be a steep learning curve. I am up for the challenge. BDCs are here to “save the day” because it gives you a “learning path.” So if you ever thought, “with so many new things on the market, what should I learn to keep my skills relevant” then this is it. Learning about BDCs will require you to learn about so many different current technologies (those mentioned above). The learning path will be a extremely steep with having to learn about Linux, Containers, Kubernetes, but in the end I truly believe it’ll be a fun journey. And MOST importantly, you can feel good about yourself knowing that you are learning cutting edge technology that will be in high demand for years to come!
My next blog post will be on how to set up a SQL Server Big Data Cluster on Azure Kubernetes Service (AKS). Feel free to sign up for my newsletter so you get BDC posts straight to your inbox. Here are a few posts to help you with your learning path: How To Install SQL Server 2019 on Linux (CentOS), How To Install Docker Desktop For Windows 10, and How To Install Docker Desktop For Mac.
You can view Part 1 of the BDC series here.
One Reply to “What Are SQL Server Big Data Clusters?”